

AI Literacy: Teach Your AI
Exploring the required data and ways to teach your AI


Welcome to the AI Literacy Mini-Series
Whilst Artificial intelligence (AI) and Machine Learning (ML) have been actively researched for many years, the recent breakthroughs in their capabilities and adoption are poised to have profound, lasting impacts on business and the world.
As part of the ‘AI Literacy’ mini-series, we will delve into key concepts and terminology you need to know to better inform your decision making, enabling you to:
Interpret and understand the latest news and developments
Gain a deeper understanding of the core mechanics that drive AI technology
How to teach you AI models
AI needs a lot of data to identify and form effective rules
Our first article explained that AI focuses on producing machines that can apply statistical models to data to identify rules, trends, or patterns and generate outputs. We will now delve into the key terms and concepts related to putting this in practice when teaching the AI model.
Key Topics Covered
Overview of the main learning methods
The data requirements for each type of learning
There are 3 common methods for an AI model to learn (form rules, patterns and trends)
Supervised Learning:
The AI model is trained on pre-classified data (labeled data - Annotated or labeled with the correct outputs or target labels) and a pre-determined loss function to assess the accuracy of its output. The AI model learns to map the input data to the corresponding output labels so as to minimise that predetermined loss function.Unsupervised Learning:
The AI model is not given any explicit guidance or classified data (unlabeled data - Does not have explicit annotations or labels and is used in Unsupervised Learning). The AI model has to apply the learning algorithm to explore the data and identify rules, relationships, clusters or trends on its own.Reinforcement Learning (RL):
Whilst the above 2 types of learning are focused on forming and identifying patterns, RL focuses on learning by interacting with the environment. This is done by equipping the AI model with reward and/or penalty functions to guide its actions and learn through trial and error. This can be applied to both Supervised and Unsupervised learning to enhance the quality of the outputs.
AI is ‘data hungry’ as your data needs to be split into 3 categories each of which plays a different role. This only goes up if more rounds of validation and testing are needed to fine-tune
Training Data Set:
A subset of your input data. This is what the AI model uses in its initial review to identify rules, patterns, and trends.Validation Data Set:
Another subset of your input data. The goal is to evaluate the AI Models performance when it is asked to face a scenario that is not covered in the training data.
This is where multiple iterations may need to be run in order to help ‘fine-tune‘ the AI model and help to prevent overfitting.Test Data Set:
The remaining data which has not been seen by the AI model until the training and validation steps are completed. This is used as a final step to assess the AI's overall performanceNote: In Reinforcement Learning, the above data types are not needed as the AI model simply needs to be able to sense the environment in which it is operating, know what actions it can take and the reward/penalty mechanisms.
However, it is possible to combine RL with Supervised and Unsupervised learning to encourage effective exploration of the data. The diagram below illustrates the different learning approaches at a high level.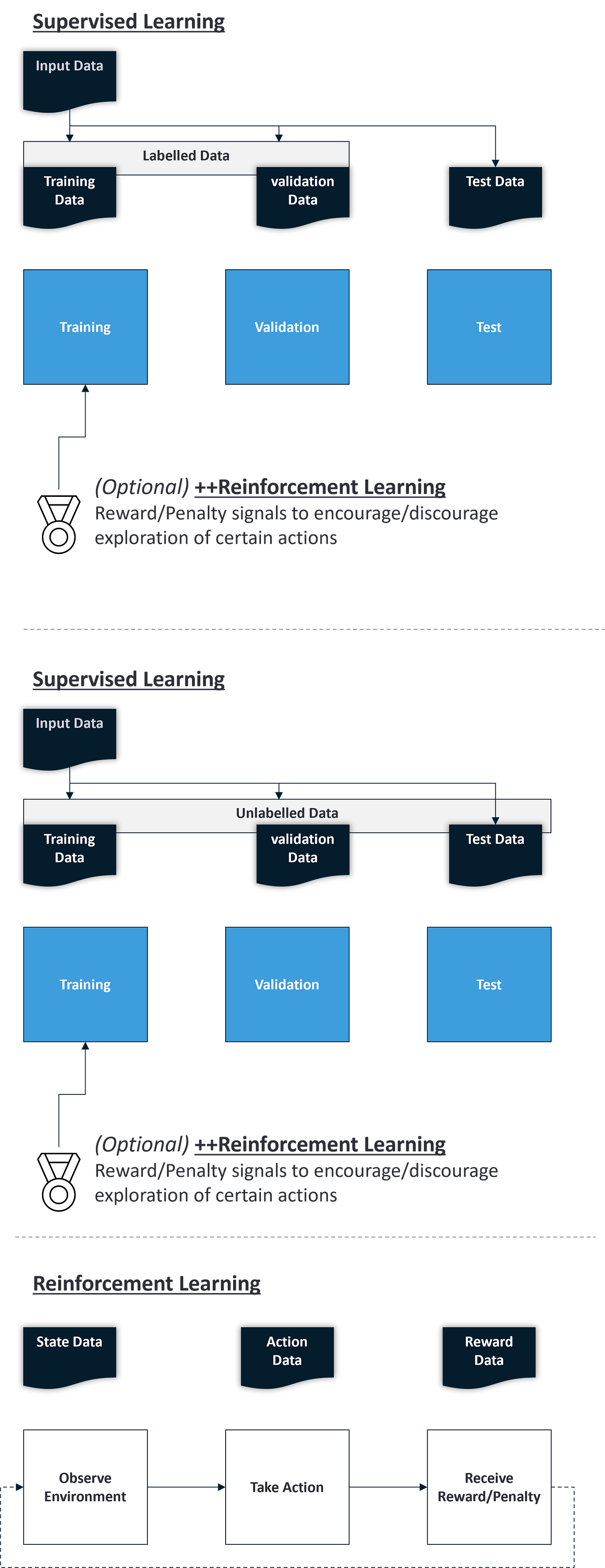
Thank you for reading! Stay tuned for the continuation of this series. The next issue we will be key concepts and terminology to support the creation of an AI model.
Follow @ExecSumFIN on twitter or Substack Note for daily news updates and notifcations.
Like what you read, refer a friend and get rewarded, or leave a like or comment.